思考: 硬币
硬币a和硬币b, 抛硬币a朝上的概率为0.7, 抛硬币b朝上的概率为0.4
问题1: 从一个黑盒中随机取出一个, 向上抛10次, 结果有6次朝上, 那么拿的是哪个硬币, 为什么?
问题2: 分别来自a和b的概率是多少?
问题3: 向上抛20次, 有12次正面朝上的概率是多少?
分析
| 硬币编号 | 硬币朝上 | 硬币朝下 |
|---|---|---|
| a | 0.7 | 0.3 |
| b | 0.4 | 0.6 |
设向上抛硬币a和b是事件A, 那么,
抛硬币a朝上的概率为0.7, 记为$P(A_1) = 0.7$, 抛硬币b朝上的概率为0.4, 记为$P(A_2) = 0.4$
向上抛10次结果有6次朝上为事件B, 记为$P(B)$
或者
向上抛20次, 12次正面朝上的概率为:
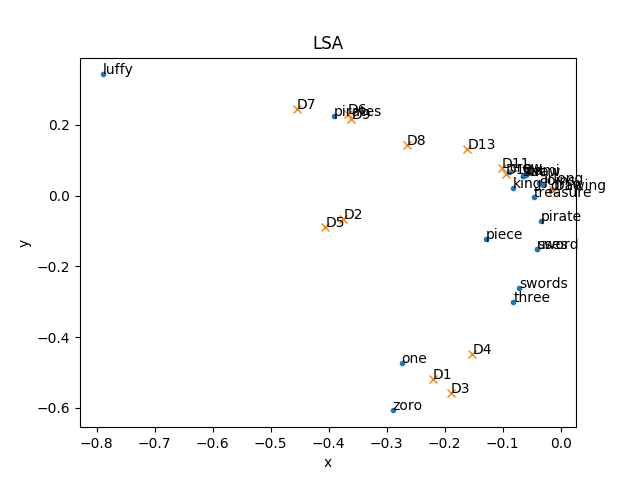
思考: 为什么SVD之后cos距离最近
几何中夹角余弦可用来衡量两个向量方向的差异, 所以可以用余弦相似度来衡量样本向量之间的差异
所以在文本做完SVD之后, 用余弦相似度来衡量输入文本中每个文档(即每句话)之间的相似度
编程: 病情预测
6位建筑工人历史病例数据如下:
| 症状 | 职业 | 疾病 |
|---|---|---|
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
根据以上历史数据, 预测新来的一位打喷嚏的建筑工人患感冒的概率
分析
从上述数据, 可以直观的得到, 症状列表为$[“打喷嚏”, “头痛”]$, 职业列表为$[“护士”, “建筑工人”, “教师”, “农夫”]$, 疾病列表为$[“感冒”, “过敏”, “脑震荡”]$
统计
如果从2种症状判断为3种疾病的关系表如下:
| 症状 | 疾病 |
|---|---|
| 打喷嚏 | 感冒 |
| 打喷嚏 | 过敏 |
| 头痛 | 脑震荡 |
| 头痛 | 感冒 |
| 打喷嚏 | 感冒 |
| 头痛 | 脑震荡 |
统计如下:
| 症状 | 疾病 | 次数 |
|---|---|---|
| 打喷嚏 | 感冒 | 2 |
| 打喷嚏 | 过敏 | 1 |
| 头痛 | 脑震荡 | 2 |
| 头痛 | 感冒 | 1 |
或者如下(将行列转置一下):
| T1(症状-疾病表) | 感冒 | 过敏 | 脑震荡 |
|---|---|---|---|
| 打喷嚏 | 2 | 1 | 0 |
| 头痛 | 1 | 0 | 2 |
如果从4种职业判断为3种疾病的关系表如下:
| 职业 | 疾病 | 次数 |
|---|---|---|
| 护士 | 感冒 | 1 |
| 农夫 | 过敏 | 1 |
| 建筑工人 | 脑震荡 | 1 |
| 建筑工人 | 感冒 | 1 |
| 教师 | 感冒 | 1 |
| 教师 | 脑震荡 | 1 |
或者如下(将行列转置一下):
| T2(职业-疾病表) | 感冒 | 过敏 | 脑震荡 |
|---|---|---|---|
| 护士 | 1 | 0 | 0 |
| 农夫 | 0 | 1 | 0 |
| 建筑工人 | 1 | 0 | 1 |
| 教师 | 1 | 0 | 1 |
从T1(症状-疾病表), 得到:
P(感冒|打喷嚏) = 2/3, P(打喷嚏|感冒) = 2/3
P(感冒|头痛) = 1/3, P(头痛|感冒) = 1/3
P(过敏|打喷嚏) = 1, P(打喷嚏|过敏) = 1/1
P(过敏|头痛) = 0, P(头痛|过敏) = 0/1
P(脑震荡|打喷嚏) = 0, P(打喷嚏|脑震荡) = 0/2
P(脑震荡|头痛) = 1, P(头痛|脑震荡) = 2/2
P(打喷嚏) = 3/6
P(头痛) = 3/6
P(感冒) = 3/6
P(过敏) = 1/6
P(脑震荡) = 2/6
| P(疾病|症状)概率表 | 感冒 | 过敏 | 脑震荡 |
|---|---|---|---|
| 打喷嚏 | 2/3 | 1 | 0 |
| 头痛 | 1/3 | 0 | 1 |
从T2(职业-疾病表), 得到:
P(感冒|护士) = 1/1, P(护士|感冒) = 1/3
P(过敏|护士) = 0/1, P(护士|过敏) = 0/1
P(脑震荡|护士) = 0/1, P(护士|脑震荡) = 0/2
P(感冒|农夫) = 0/1, P(农夫|感冒) = 0/3
P(过敏|农夫) = 1/1, P(农夫|过敏) = 1/1
P(脑震荡|农夫) = 0/1, P(农夫|脑震荡) = 0/2
P(感冒|建筑工人) = 1/2, P(建筑工人|感冒) = 1/3
P(过敏|建筑工人) = 0/2, P(建筑工人|过敏) = 0/1
P(脑震荡|建筑工人) = 1/2, P(建筑工人|脑震荡) = 1/2
P(感冒|教师) = 1/2, P(教师|感冒) = 1/3
P(过敏|教师) = 0/2, P(教师|过敏) = 0/1
P(脑震荡|教师) = 1/2, P(教师|脑震荡) = 1/2
P(护士) = 1/6
P(农夫) = 1/6
P(建筑工人) = 2/6
P(教师) = 2/6
P(感冒) = 3/6
P(过敏) = 1/6
P(脑震荡) = 2/6
计算结果
编程实现
history.csv1
2
3
4
5
6
7症状,职业,疾病
打喷嚏,护士,感冒
打喷嚏,农夫,过敏
头痛,建筑工人,脑震荡
头痛,建筑工人,感冒
打喷嚏,教师,感冒
头痛,教师,脑震荡
predict_sick.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88import numpy as np
import pandas as pd
"""
症状列表:
[“打喷嚏”,“头痛”]
职业列表:
[“护士”,“建筑工人”,“教师”,“农夫”]
疾病列表:
[“感冒”,“过敏”,“脑震荡”]
历史数据:
症状, 职业, 疾病
打喷嚏, 护士, 感冒
打喷嚏, 农夫, 过敏
头痛, 建筑工人, 脑震荡
头痛, 建筑工人, 感冒
打喷嚏, 教师, 感冒
头痛, 教师, 脑震荡
"""
data = pd.read_csv('history.csv')
print(data)
sickness = data["疾病"].value_counts()
occupation = data["职业"].value_counts()
symptom = data["症状"].value_counts()
print(sickness)
print(occupation)
print(symptom)
# P(打喷嚏)
p_pengti = symptom["打喷嚏"] / sum(symptom)
print(f"p_pengti:\n {p_pengti}")
# P(建筑工人)
p_worker = occupation["建筑工人"] / sum(occupation)
print(f"p_worker:\n {p_worker}")
# P(感冒)
p_cold = sickness["感冒"] / sum(sickness)
print(f"p_cold:\n {p_cold}")
# P(建筑工人|感冒)
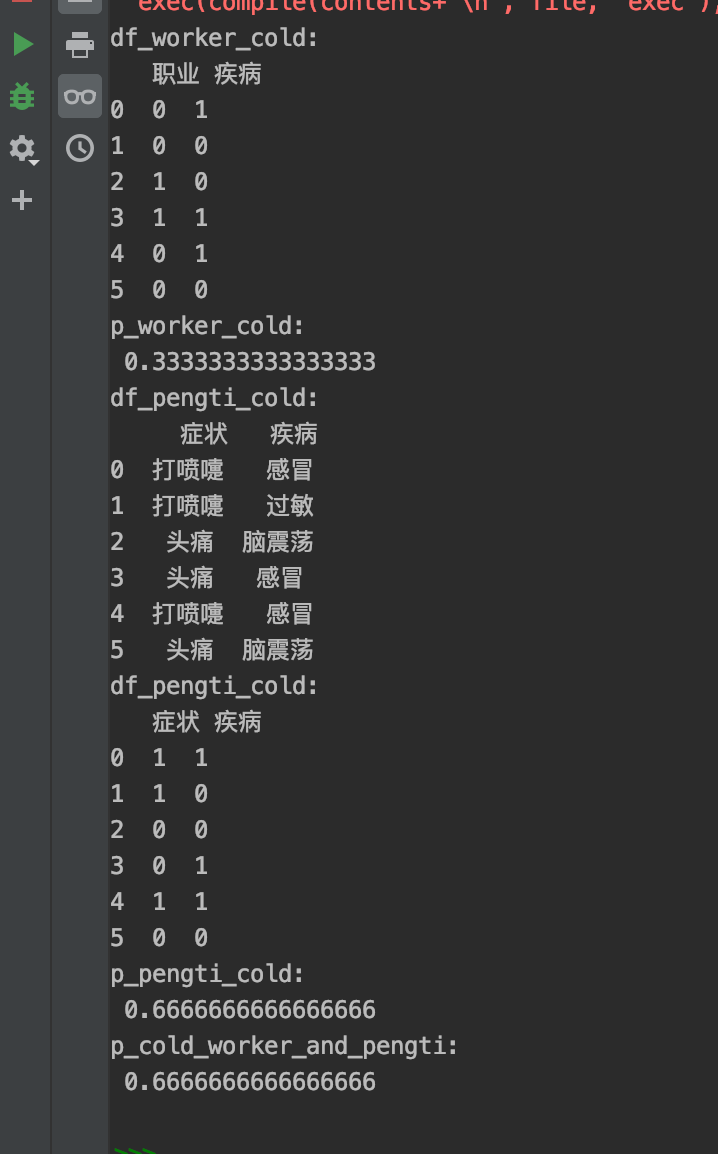
df_worker_cold = data[["职业", "疾病"]]
print(f"df_worker_cold:\n {df_worker_cold}")
for index, row in df_worker_cold.iterrows():
if row["疾病"] == "感冒":
df_worker_cold["疾病"][index] = 1
if row["职业"] == "建筑工人":
df_worker_cold["职业"][index] = 1
else:
df_worker_cold["职业"][index] = 0
else:
df_worker_cold["疾病"][index] = 0
if row["职业"] == "建筑工人":
df_worker_cold["职业"][index] = 1
else:
df_worker_cold["职业"][index] = 0
print(f"df_worker_cold:\n {df_worker_cold}")
p_worker_cold = (df_worker_cold["职业"] & df_worker_cold["疾病"]).sum() / df_worker_cold["疾病"].sum()
print(f"p_worker_cold:\n {p_worker_cold}")
# P(打喷嚏|感冒)
df_pengti_cold = data[["症状", "疾病"]]
print(f"df_pengti_cold:\n {df_pengti_cold}")
for i, j in df_pengti_cold.iterrows():
# print(i, j)
if j["疾病"].strip() == "感冒":
df_pengti_cold["疾病"][i] = 1
if j["症状"] == "打喷嚏":
df_pengti_cold["症状"][i] = 1
else:
df_pengti_cold["症状"][i] = 0
else:
df_pengti_cold["疾病"][i] = 0
if j["症状"] == "打喷嚏":
df_pengti_cold["症状"][i] = 1
else:
df_pengti_cold["症状"][i] = 0
print(f"df_pengti_cold:\n {df_pengti_cold}")
p_pengti_cold = (df_pengti_cold["症状"] & df_pengti_cold["疾病"]).sum() / df_pengti_cold["疾病"].sum()
print(f"p_pengti_cold:\n {p_pengti_cold}")
# P(感冒|建筑工人,打喷嚏)
p_cold_worker_and_pengti = (p_worker_cold * p_pengti_cold * p_cold) / (p_worker * p_pengti)
print(f"p_cold_worker_and_pengti:\n {p_cold_worker_and_pengti}")
编程: 在SVD基础上进行TF-IDF
- 将一个文本当作一个无序的数据集合, 文本特征可以采用文本中的词条T进行体现, 那么文本中出现的所有词条及其出现的次数就可以体现文档的特征
- TF-IDF, 词条的重要性随着它在文件中出现的次数成正比增加, 但同时会随着它在语料库中出现的频率成反比下降;
- 词条在文本中出现的次数越多, 表示该词条对该文本的重要性越高
- 词条在所有文本中出现的次数越少, 说明这个词条对文本的重要性越高
- TF(词频)指某个词条在文本中出现的次数, 一般会将其进行归一化处理(该词条数量/该文档中所有词条数量)
- IDF(逆向文件频率)指一条词条重要性的度量, 一般计算方式为总文件数目除以包含该词语之文件的数目, 再将得到的商取对数得到. TF-IDF即TF*IDF
注意: IDF取对数时,分母$+1$是为了方式分母为0
tf-idf-svd.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146import numpy as np
import pylab
import re
from scipy import linalg
from matplotlib import pyplot
# 文档
documents = [
"Roronoa Zoro, nicknamed \"Pirate Hunter\" Zoro, is a fictional character in the One Piece franchise created by Eiichiro Oda.",
"In the story, Zoro is the first to join Monkey D. Luffy after he is saved from being executed at the Marine Base. ",
"Zoro is an expert swordsman who uses three swords for his Three Sword Style, but is also capable of the one and two-sword styles. ",
"Zoro seems to be more comfortable and powerful using three swords, but he also uses one sword or two swords against weaker enemies.",
"In One Piece, Luffy sails from the East Blue to the Grand Line in search of the legendary treasure One Piece to succeed Gol D. Roger as the King of the Pirates. ",
"Luffy is the captain of the Straw Hat Pirates and along his journey, he recruits new crew members with unique abilities and personalities. ",
"Luffy often thinks with his stomach and gorges himself to comical levels. ",
"However, Luffy is not as naive as many people believe him to be, showing more understanding in situations than people often expect. ",
"Knowing the dangers ahead, Luffy is willing to risk his life to reach his goal to become the King of the Pirates, and protect his crew.",
"Adopted and raised by Navy seaman turned tangerine farmer Bellemere, Nami and her older sister Nojiko, have to witness their mother being murdered by the infamous Arlong.",
"Nami, still a child but already an accomplished cartographer who dreams of drawing a complete map of the world, joins the pirates, hoping to eventually buy freedom for her village. ",
"Growing up as a pirate-hating pirate, drawing maps for Arlong and stealing treasure from other pirates, Nami becomes an excellent burglar, pickpocket and navigator with an exceptional ability to forecast weather.",
"After Arlong betrays her, and he and his gang are defeated by the Straw Hat Pirates, Nami joins the latter in pursuit of her dream."
]
print(f'len(documents): {len(documents)}')
# 停用词
stopwords = ['a', 'an', 'after', 'also', 'and', 'as', 'be', 'being', 'but', 'by', 'd', 'for', 'from', 'he', 'her',
'his', 'in', 'is', 'more', 'of', 'often', 'the', 'to', 'who', 'with', 'people']
# 要去除的标点符号的正则表达式
punctuation_regex = '[,.;"]+'
# 构建一个字典, key是单词, value是单词出现的文档编号
dictionary = {}
# 当前处理的文档编号
currentDocId = 0
# 语料库的文档总数
documents_total = len(documents)
# 文档的总词数, 用来记录每篇文档的总词数
documents_len = dict()
# 依次处理每篇文档
for d in documents:
words = d.split()
# 初始化每篇文档总词数
words_count = 0
for w in words:
# 去标点
w = re.sub(punctuation_regex, '', w.lower())
if w in stopwords:
continue
elif w in dictionary:
dictionary[w].append(currentDocId)
else:
dictionary[w] = [currentDocId]
words_count += 1
documents_len[currentDocId] = words_count
currentDocId += 1
print(f"dictionary: {dictionary}")
print(f"语料库的文档总数documents_total: {documents_total}")
print(f"每篇文档的总词数documents_len: {documents_len}")
# tf = 某个词在文章中出现的次数 / 文章的总词数
# idf = log (语料库的文档总数 / (包含该词的文档数 + 1))
idf_dict = dict()
print(f"documents: {documents}")
import math
for k, v in dictionary.items():
idf_dict[k] = math.log2(float(documents_total) / float((len(v) + 1)))
# 至少出现在两个文档中的单词选为关键词
keywords = [k for k in dictionary.keys() if len(dictionary[k]) > 1]
print(f'keywords: {len(keywords)}, {keywords}')
keywords.sort()
print(f'keywords: {len(keywords)}, {keywords}')
# 生成word-document矩阵[19, 13]
X = np.zeros([len(keywords), currentDocId])
print(f'X: {X}')
for i, k in enumerate(keywords):
countWordDocument = {}
for d in dictionary[k]:
if d in countWordDocument:
countWordDocument[d] += 1
else:
countWordDocument[d] = 1
for d, v in countWordDocument.items():
tf = float(v) / (documents_len[d])
idf = idf_dict[k]
tf_idf = tf / idf
X[i, d] += tf_idf
# X[i, d] += 1
print(f'X: {X}')
# 奇异值分解
U, sigma, V = linalg.svd(X, full_matrices=True)
print("U:\n", U.shape, "\n", U, "\n")
print("SIGMA:\n", sigma.shape, sigma, "\n")
print("V:\n", V.shape, V, "\n")
# 得到降维(降到targetDimension维)后单词与文档的坐标表示
targetDimension = 2
U2 = U[0:, 0:targetDimension]
V2 = V[0:targetDimension, 0:]
sigma2 = np.diag(sigma[0:targetDimension])
print(f"U.shape: {U.shape}, sigma.shape: {sigma.shape}, V.shape: {V.shape}")
print(f"U2.shape: {U2.shape}, sigma2.shape: {sigma2.shape}, V2.shape: {V2.shape}")
# 对比原始矩阵与降维结果
X2 = np.dot(np.dot(U2, sigma2), V2)
print("X:\n", X)
print("X2:\n", X2)
# 开始画图
pyplot.title("LSA")
pyplot.xlabel(u'x')
pyplot.ylabel(u'y')
# 绘制单词表示的点
# U2的每一行包含了每个单词的坐标表示(维度是targetDimension),此处使用前两个维度的坐标画图
for i in range(len(U2)):
pylab.text(U2[i][0], U2[i][1], keywords[i], fontsize=10)
print("(", U2[i][0], ",", U2[i][1], ")", keywords[i])
x = U2.T[0]
y = U2.T[1]
pylab.plot(x, y, '.')
# 绘制文档表示的点
# V2的每一列包含了每个文档的坐标表示(维度是targetDimension),此处使用前两个维度的坐标画图
Dkey = []
for i in range(len(V2[0])):
pylab.text(V2[0][i], V2[1][i], ('D%d' % (i + 1)), fontsize=10)
print("(", V2[0][i], ",", V2[1][i], ")", ('D%d' % (i + 1)))
Dkey.append('D%d' % (i + 1))
x = V[0]
y = V[1]
pylab.plot(x, y, 'x')
pylab.savefig("tf-idf-svd.png", dpi=100)
exit()