Inception
Inception结构
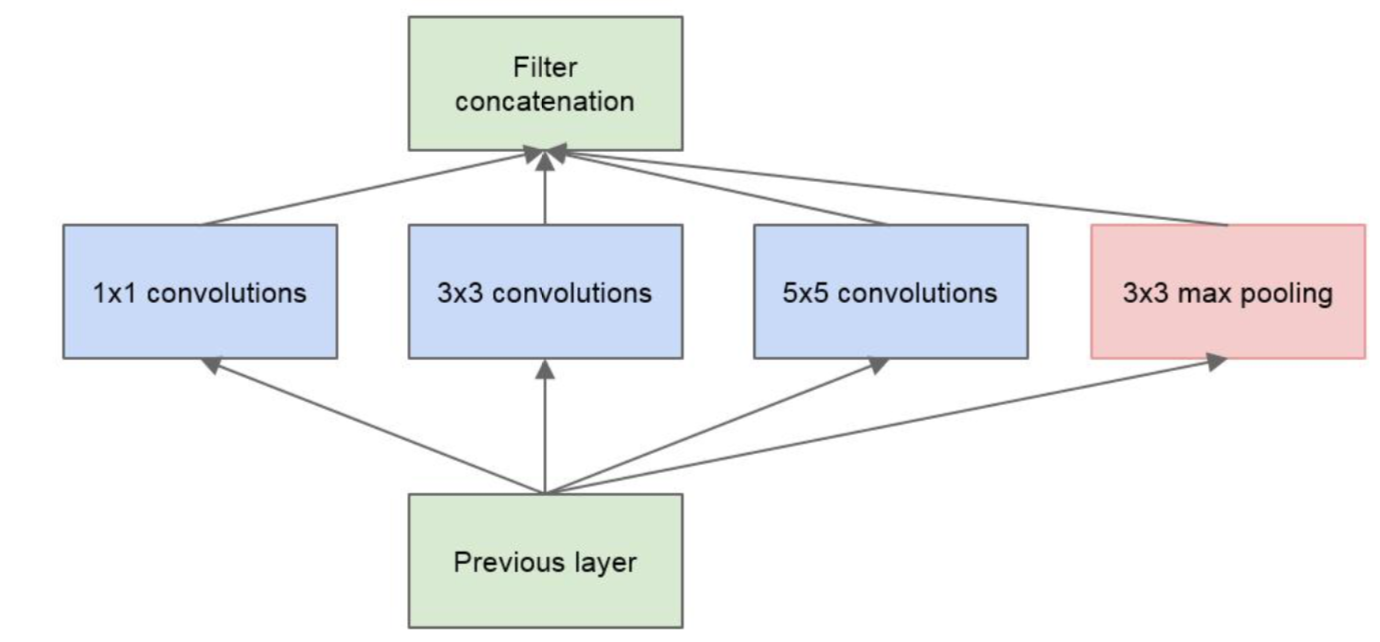
Inception架构的主要思想是找出如何让已有的稠密组件接近与覆盖卷积视觉网络中的最佳局部稀疏结构
为了避免patch校准问题, 现在滤波器大小限制在$1\ast1$, $3\ast3$和$5\ast5$, 主要为了方便, 不是必要的
另外在pooling层添加一个额外的并行pooling路径用于提高效率
Previous Layer, 输入层, 比如是$27\ast27\ast128$
先做一个$1\ast1$的卷积, 那么output为: $(27-1+1)/1=27, 27\ast27\ast?$
$3\ast3$的卷积, output为: $(27-3+1+2)/1=27, 27\ast27\ast?$
$5\ast5$的卷积, output为: $(27-5+1+4)/1=27, 27\ast27\ast?$
以上的三个卷积相当于从三个不同的方面并行的观察目标信息, 在这里比如$1\ast1$是10个, $3\ast3$是20个, $5\ast5$是5个, 那么输出到filter concatenation就是$27\ast27\ast35$, 就包含了小/中/大区域观测的结果
然而, 输入结果中有可能也包含着一些个性化的或者噪音数据或者异常信息, 所有要并行的做一个池化操作
池化的output为: (27-3+1+2)/1, 池化不改变深度, 所以是$27\ast27\ast128$
所以最后的层次为$27\ast27\ast(35+128)=27\ast27\ast163$
参数量为$(1\ast1\ast128+1)\ast10 + (3\ast3\ast128+1)\ast20 + (5\ast5\ast128+1)\ast5 = 40355$
这种结构参数比较多, 遂引出inception的改进结构
Inception结构改进/Pointwise Conv
架构的第二个主要思想: 在计算要求增加很多的地方应用维度缩减和预测. 即在$3\ast3$和$5\ast5$卷积前用一个$1\ast1$的卷积用于减少计算, 还用于修正线性激活. 如下图所示, 左边是加入维度缩减之前的, 右边是加入维度缩减之后的, 这就是Inception V1的网络架构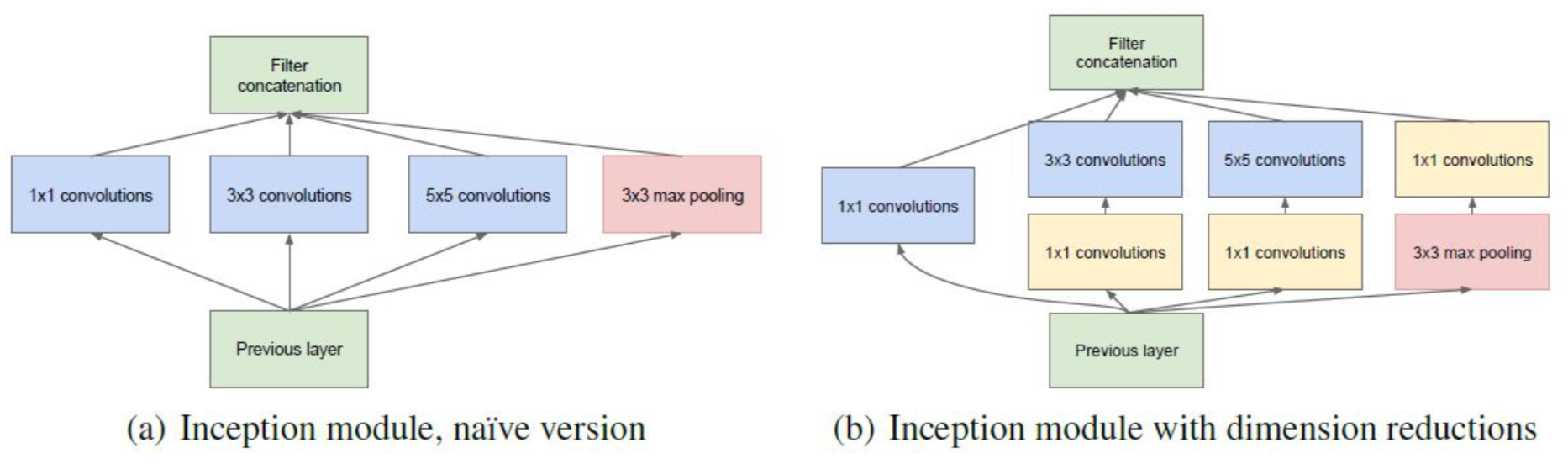
输入还是$27\ast27\ast128$, 假设核函数设置的都是10个
那么未改进的结构的总层数为$27\ast27\ast(10+10+10+128)=27\ast27\ast158$
参数量为$(1\ast1\ast128+1)\ast10 + (3\ast3\ast128+1)\ast10 + (5\ast5\ast128+1)\ast10 = 44830$
改进后的总层数为$27\ast27\ast40$
参数量为$(1\ast1\ast128+1)\ast10\ast4 + (3\ast3\ast10+1)\ast10 + (5\ast5\ast10+1)\ast10 = 8580$
改进后的结构就叫做Network-In-Network, 在上面的例子来说, 就是把128个方位的降为了40个方位
在这里$1 \ast 1$的卷积核就是Pointwise Convolution, 简称PW, 其目的主要在于减少维度, 还可以引入更多的非线性
Kernel Replace
Inception V2和Inception V3为了进一步降低卷积参数采用小卷积来代替大卷积
大尺寸的卷积核可以带来更大的感受野, 但也意味着会产生更多的参数, 比如$5 \ast 5$卷积核的参数有25个, $3 \ast 3$ 卷积核的参数有9个, 前者是后者的$\frac{25}{9}=2.78$倍. 因此, GoogLeNet团队提出可以用2个连续的$3 \ast 3$卷积层组成的小网络来代替单个的$5 \ast 5$卷积层, 即在保持感受野范围的同时又减少了参数量. 除了规整的的正方形, 还有分解版本的$3 \ast 3 = 3 \ast 1 + 1 \ast 3$,这个效果在深度较深的情况下比规整的卷积核更好(feature map大小建议在12到20之间)
Group Conv/Depthwise Separable Conv
Group COnv
Group Conv分组卷积, 可以用来切分网络, 以便在多个GPU上运行
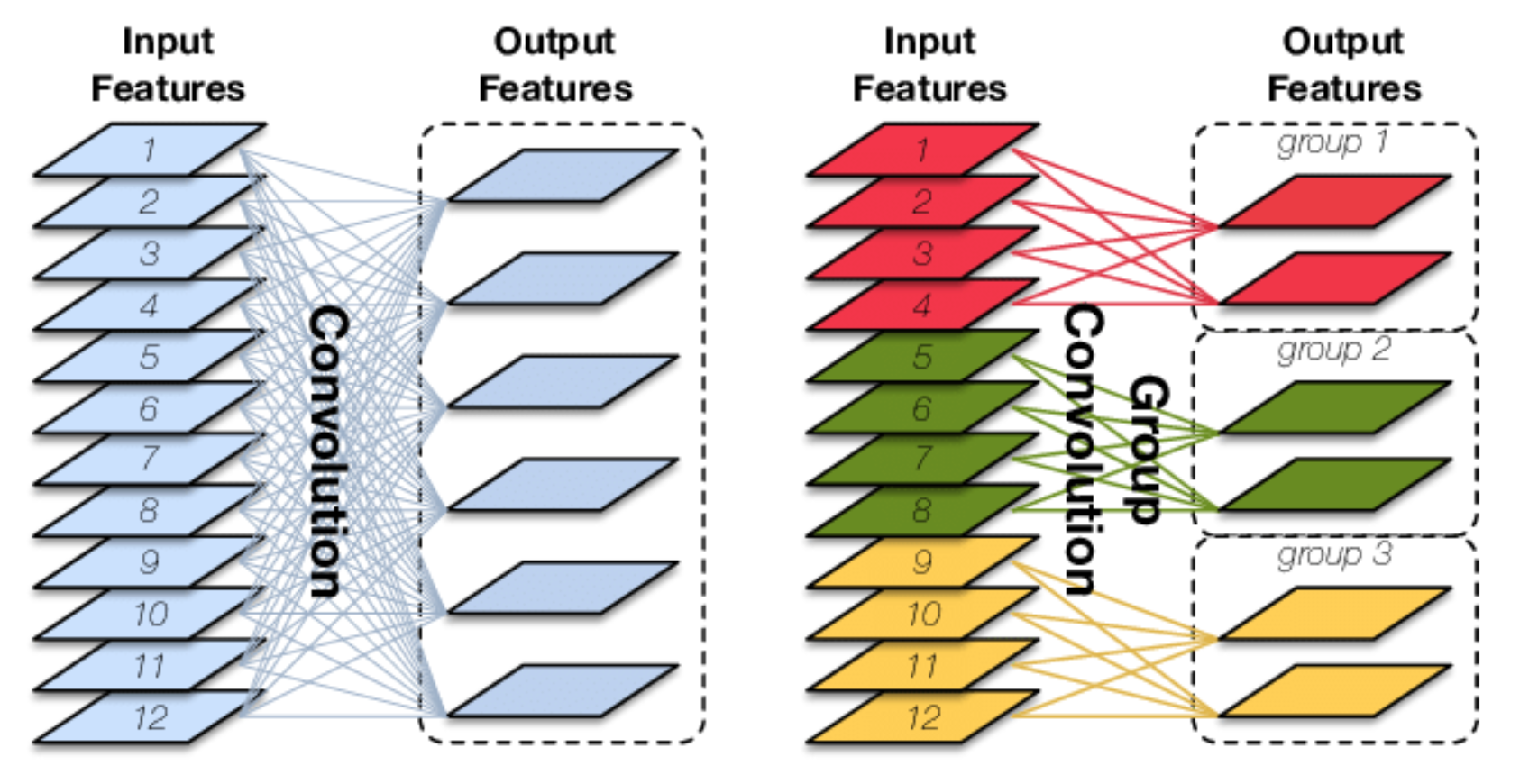
对于输入为$I \ast H \ast W$大小的input features, 经过O个$K \ast K \ast I$大小的卷积核之后, 输出的output features通道数为O, 卷积参数量为$O \ast K \ast K \ast I$
Group Conv, 先对输入的input features进行分组, 然后对每组分别进行卷积. 仍然假设input feature map的尺寸为$I \ast H \ast W$, 输出output features的通道数为O, 假设分成G个组, 则每个input feature map的数量为$\frac{I}{G}$, 每组的输出的feature map的数量为$\frac{O}{G}$, 那么每个卷积核的尺寸为$K \ast K \ast \frac{I}{G}$, 每组卷积核的数量为$\frac{O}{G}$, 卷积核的总数仍然为O.
卷积核只与自己同组的input feature map进行卷积, 最后的卷积的总参数量为$O \ast K \ast K \ast \frac{I}{G}$, 由此可以看到总参数量减少到了原来的$\frac{1}{G}$
Group Conv的用途如下所示:
- 减少参数量, 分成G组, 则参数量减少为原来的$\frac{1}{G}$
- Group Conv可以看成是一种structured sparse, 每个卷积核的尺寸由$K \ast K \ast I$变成了$K \ast K \ast \frac{I}{G}$, 那么减少的参数量为$(I - \frac{I}{G})$, 可以视其为0()
Depthwise Convolution(DW)是Group Conv的一种特例. 当分组数量等于input feature map的数量, output feature map数量也等于input feature map数量, 即当$I = O = G$, 且O个卷积核中每个的尺寸为$K \ast K \ast 1$时, Group Conv 就成了Depthwise Conv.
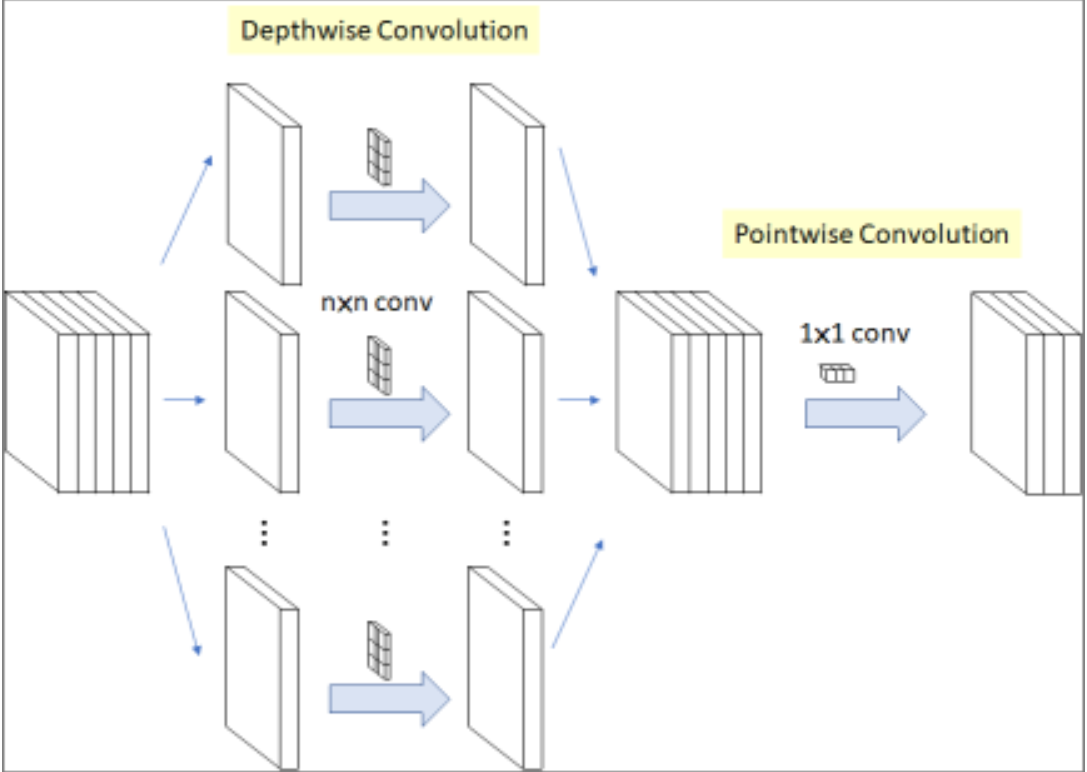
Depthwise Separable Conv
Depthwise Separable Convolution则是DW + PW的组合, 参数量会进一步缩小, 如下图所示:
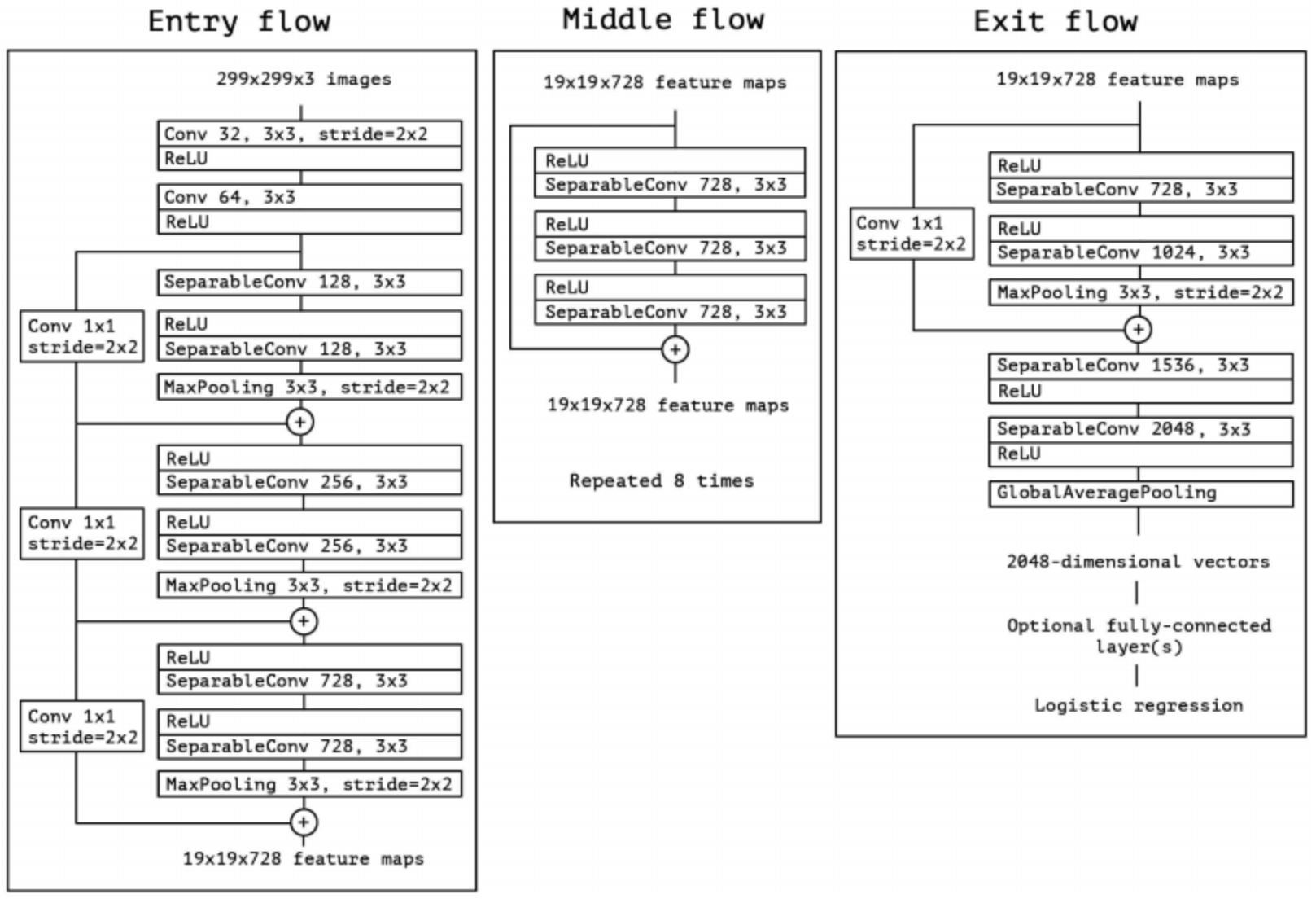
Xception
Xception就是在Inception + Depthwise Separable Conv
Inception Hypothesis
从Inception的各种演进架构可以看出, Inception V1是从多尺寸卷积核角度来观察input feature map, Inception V3是从参数量和计算量角度来尝试改进结构的.
然而Inception V3也可以理解为: 通过显式地将操作分解为一系列独立的通道维度和空间维度的学习, 从而使得学习的过程更加简单和高效.
Inception V1里各个卷积核需要同时学习空间上的相关性和通道相关性, 结合了spatial dimentions和channels dimentions.
Inception V3先通过一组$1 \ast 1$PW卷积来学习通道相关性, 将输入数据映射到多个单独的小空间(降维), 之后对所有这些小空间, 通过常规的$3 \ast 3$卷积和$5 \ast 5$卷积来学习空间相关性.
Inception背后的基本假设是, 通道相关性和空间相关性是可以分离相互之间的耦合性的, 于是就得到了Xception: 将通道相关性和空间相关性分开学习的结构.
Extreme Inception
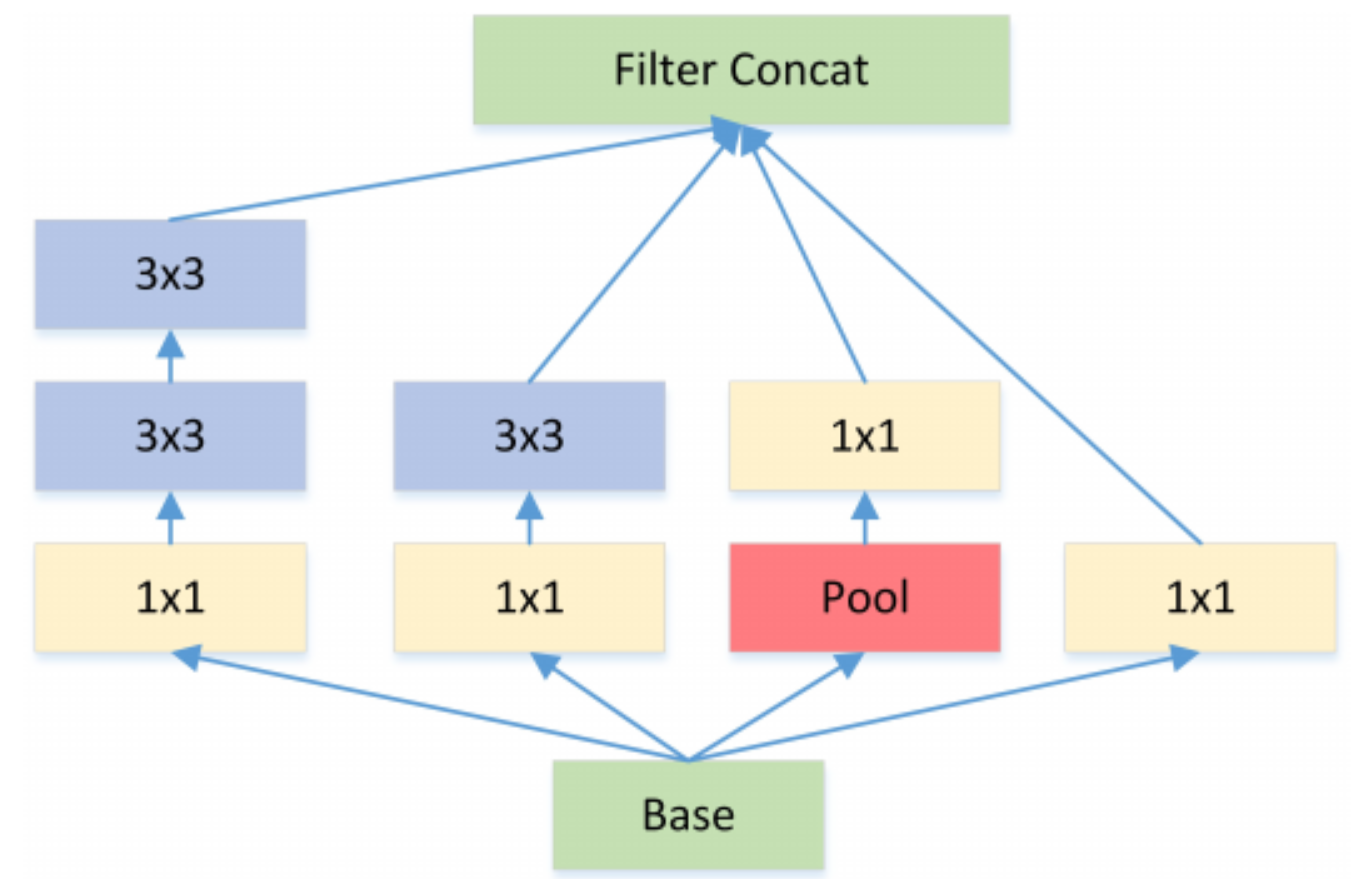
Inception中, 特征是通过$1 \ast 1$, $3 \ast 3$, $5 \ast 5$, max pooling等进行提取的, Inception结构将特征类型的选择留给网络自己训练, 即同一个输入交由几种特征提取方式, 之后做concat. Inception V3结果图如下:
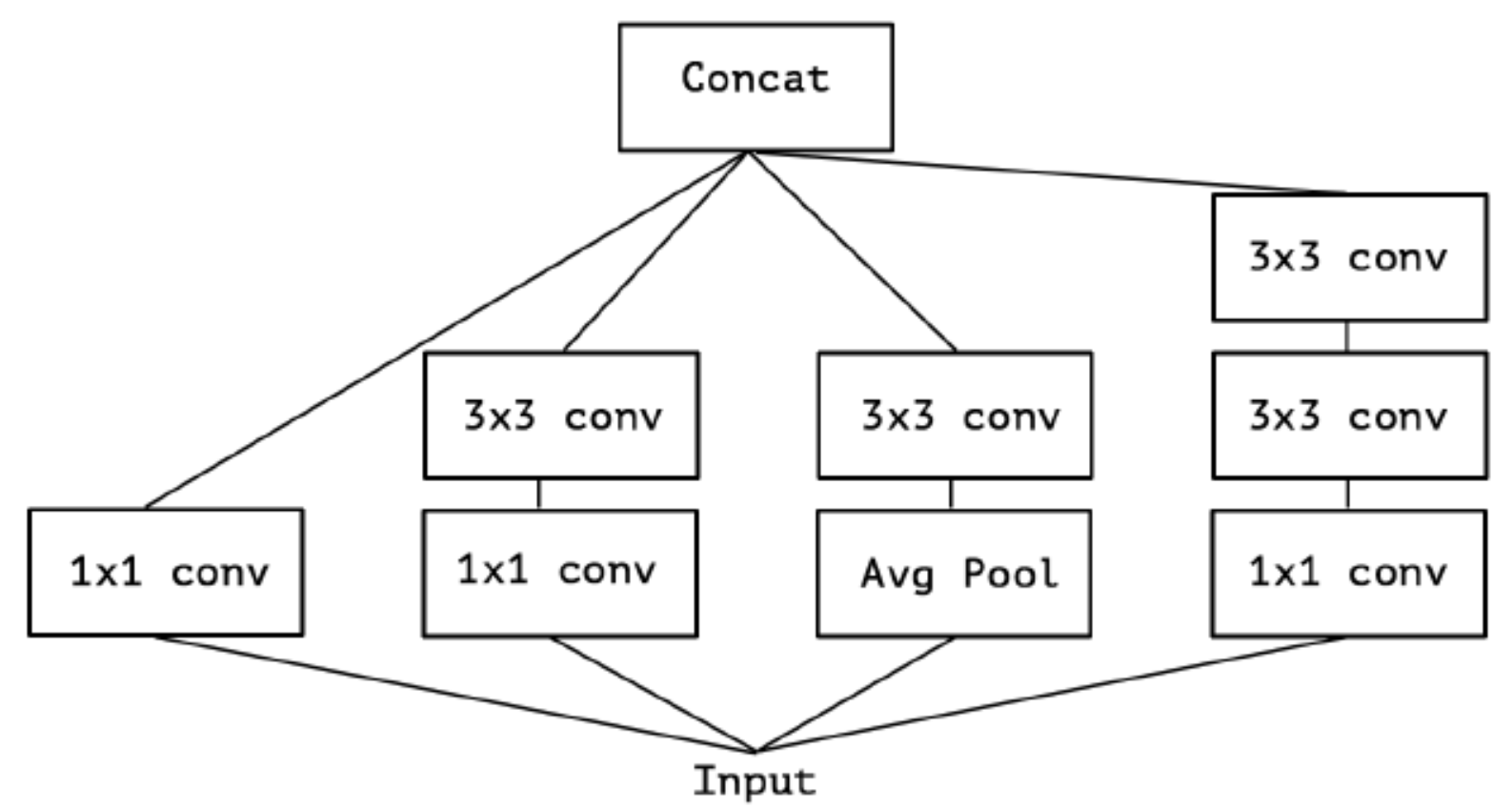
对Inception-V3进行简化, 去除Inception-V3中的avg-pooling, 输入的下一步操作就都是$1 \ast 1$的PW卷积了:
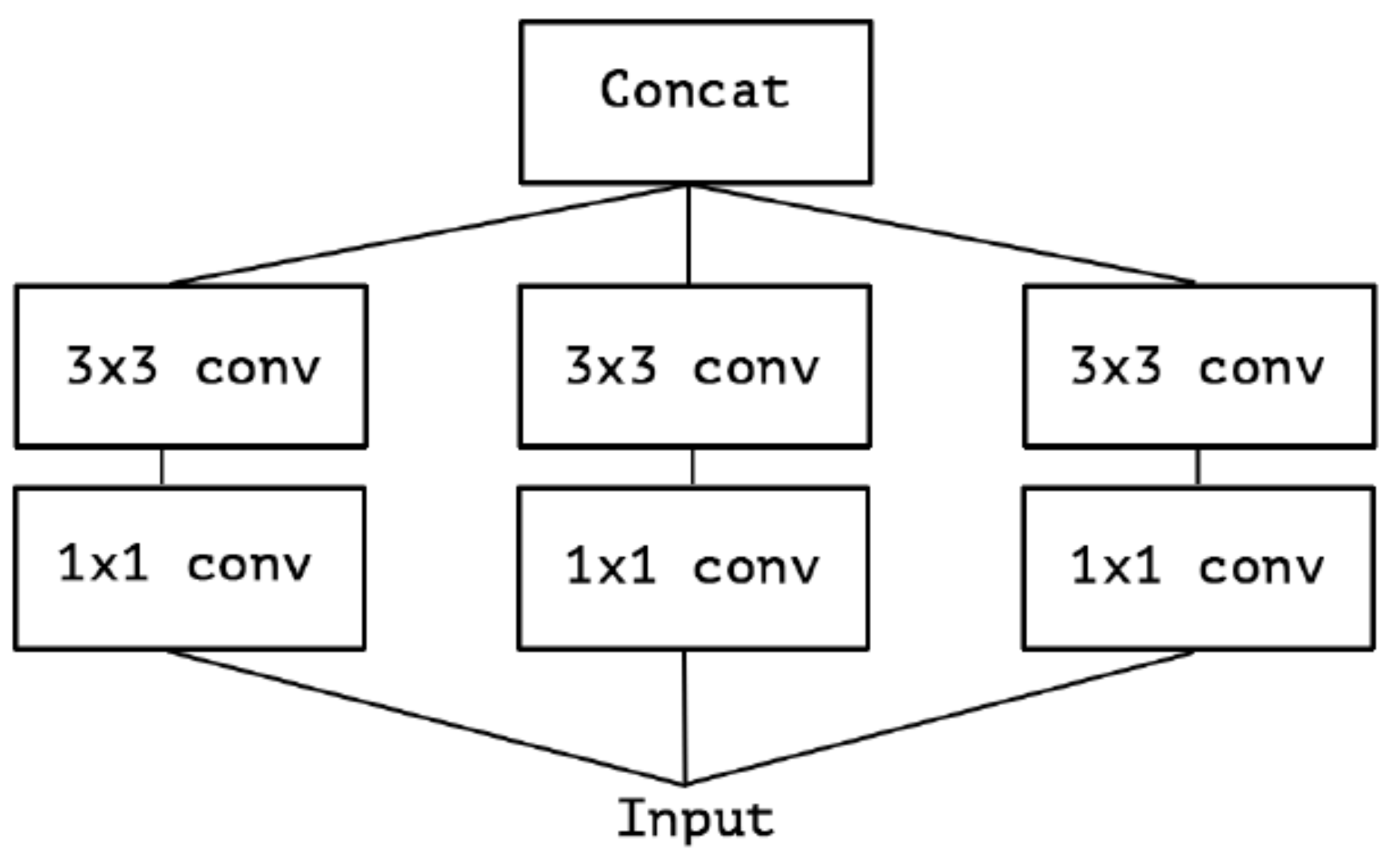
继续演进, 3个PW卷积核统一起来变成共用一个PW卷积, 后面的三个$3 \ast 3$卷积核则分别负责Group Conv
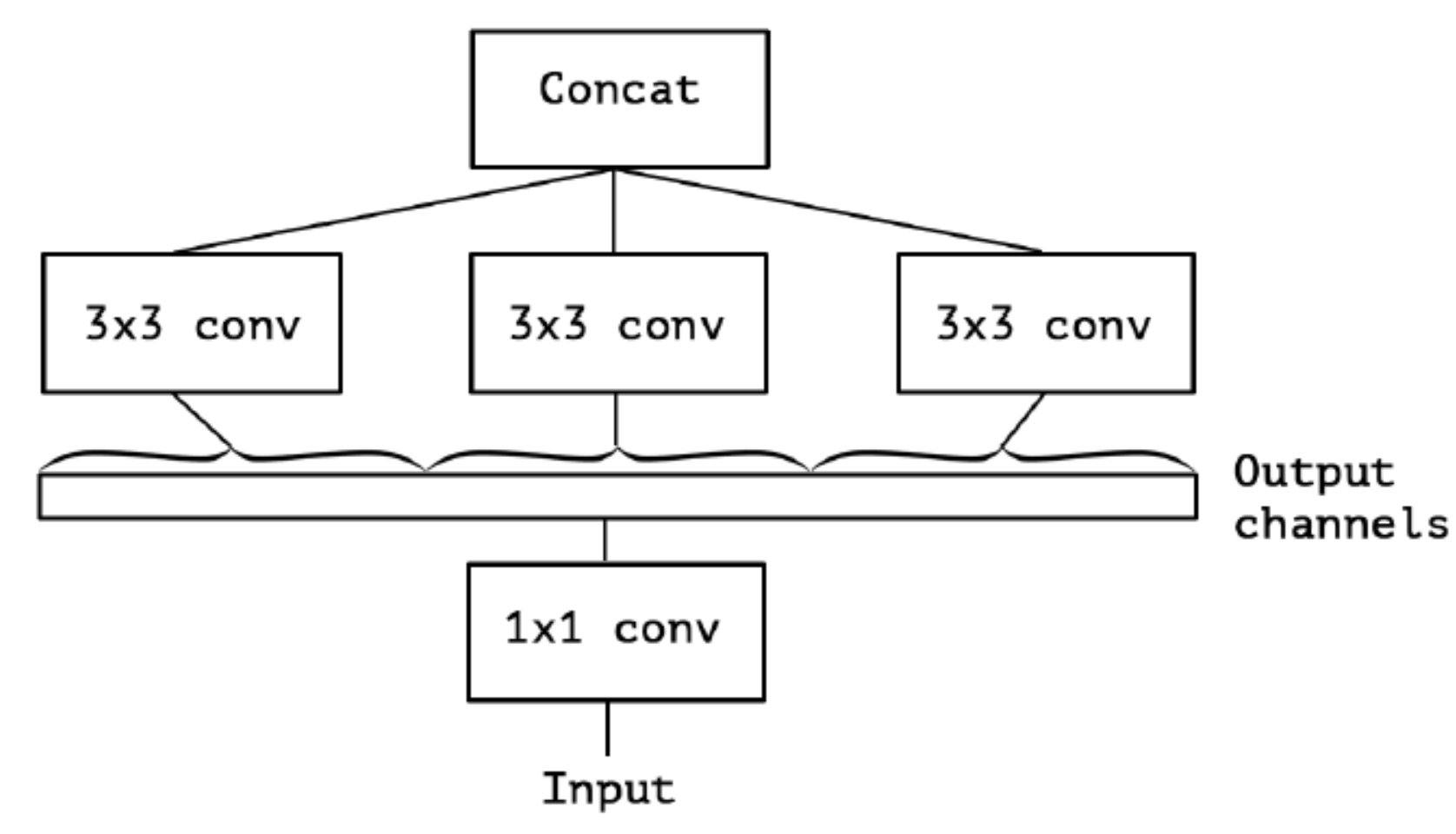
对卷积后的每个channel分别进行$3 \ast 3$卷积操作(Depthwise Conv, DW), 最后concat, 就是Extreme Inception:
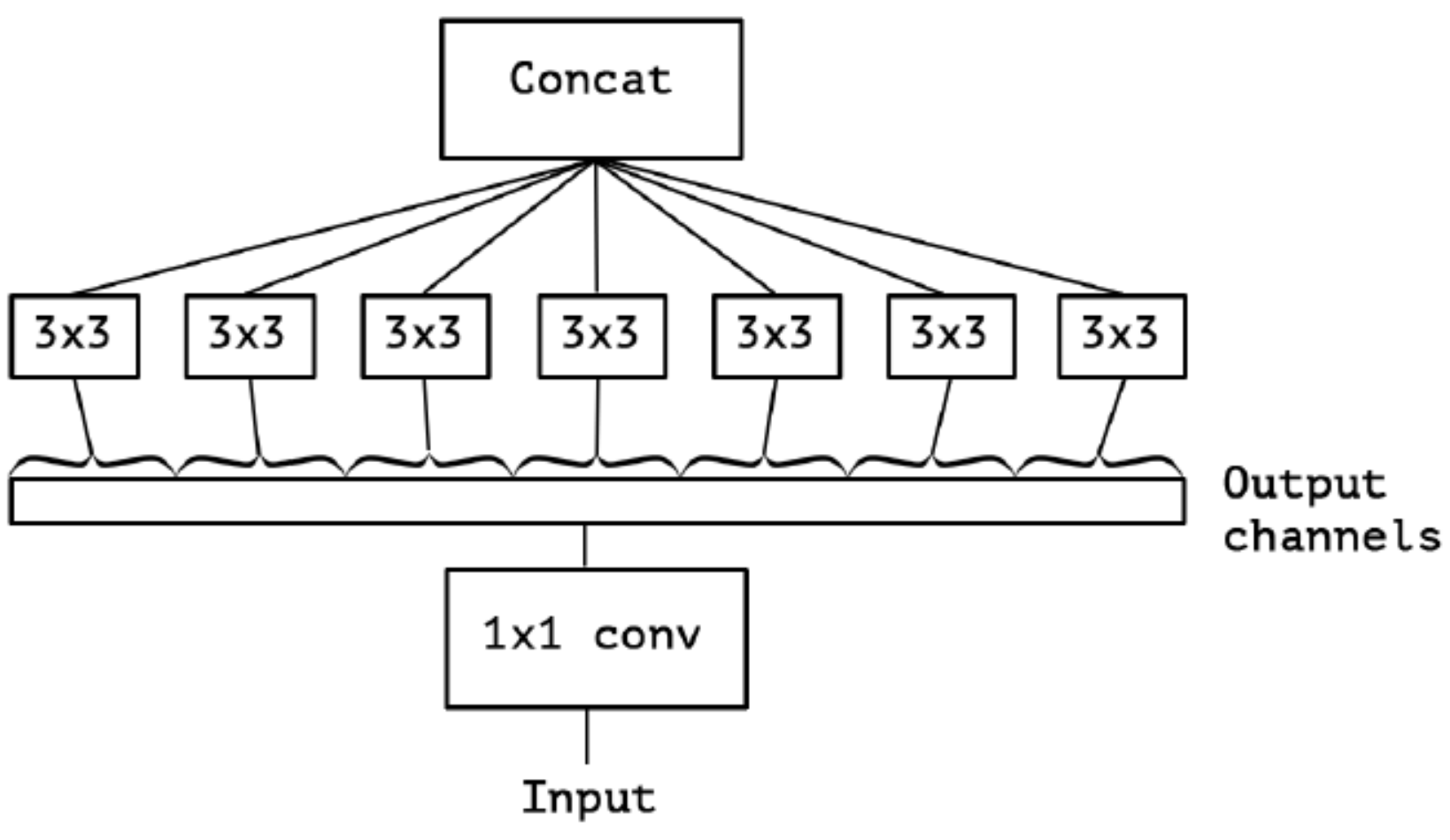
在Extreme Inception模块中, 用于学习空间相关性的$3 \ast 3$的DW卷积, 和用于学习通道相关性的$1 \ast 1$PW卷积之间, 不使用非线性激活函数, 收敛过程更快, 准确率更高.
Xception
Xception常用版本是将DW和PW互换位置.
Extreme Inception先进行$1 \ast 1$的PW卷积, 再进行$3 \ast 3$的DW卷积.
Depthwise Seprable Conv先进行$3 \ast 3$的DW卷积, 再进行$1 \ast 1$的PW卷积.
DW与标准卷积操作的计算量比较如下:
其中I为输入通道数, O为输出通道数, K为标准卷积和大小. 当使用$3 \ast 3$的卷积核时, 参数量约等于标准卷积核的$\frac{1}{9}$, 大大的减少了参数量, 从而加快了训练速度. 最终其网络结构图如下图所示: