机器学习分类维度一
- 有监督学习
- 无监督学习
- 半监督学习
机器学习分类维度二
- 分类
- 聚类
- 回归
- 关联规则
模型训练及测试
- 模型选择, 对特定任务最优建模方法的选择或者对特定模型最佳参数的选择
- 在训练数据集上运行模型(算法)并在测试数据集中测试效果, 迭代进行数据模型对修改, 这种方式称为交叉验证(将原始数据分为训练集和测试集, 使用训练集构建模型, 并使用测试集评估模型提供修改意见)
- 模型的选择会尽可能多的选择算法进行执行, 并比较执行结果
- 模型的测试一般从以下几个方面来进行比较, 分别是准确率, 召回率, 精准率, F值
- 准确率(Accuracy) = 提取出的正确样本数/总样本数
- 召回率(Recall) = 正确的正例样本数/样本中的正例样本数- 覆盖率
- 精确度(Precision) = 正确的正例样本数/预测为正例的样本数
- F值 = Precision Recall 2 / (Precision + Recall), 即F值是精准度和召回率的调和平均值
| 预测值 | |||
|---|---|---|---|
| 正例 | 负例 | ||
| 真实值 | 正例 | true positive真正例(A) | false negative假负例(B) |
| 负例 | false positive假正例(C) | true negative真负例(D) |
true positive(hit)真正例, 确实是正例
true negative(Correct Rejection)真负例, 确实是负例
false positive(False Alarm)假正例, 本来真实值是负例, 被预测为正例了, 虚报, 干扰报警
false negative(Miss)假负例, 本来真实值是正例, 被预测为负例了, 即没有预测出来
击中(Hit)(报准)和正确拒绝(Correct Rejection)是正确反应, 虚报(False Alarm)和漏报(Miss)是错误反应
A和D预测正确, B和C预测错误, 那么计算结果为:
举个例子, 真实值中, 正例为80, 负例为20; 预测值中, 正例为90, 负例为10, 然而, 在模型的实际预测中, 原本有75个真正的正例, 有15个是假正例, 5个假负例和5个真负例, 如下图所示:
| 预测值 | |||
|---|---|---|---|
| 正例90 | 负例10 | ||
| 真实值 | 正例80 | 真正例(A)75 | 假负例(B)5 |
| 负例20 | 假正例(C)15 | 真负例(D)5 |
Accuracy和Recall是一对互斥的关系, Accuracy在增大的时候Recall是在减小的
ROC
ROC(Receiver Operating Characteristic), 描述的是分类混淆矩阵中FPR-TPR之间的相对变化情况.
纵轴是TPR(True Positive Rate), 横轴是FPR(False Positive Rate)
如果二元分类器输出的是对正样本对一个分类概率值, 当取不同阈值时会得到不同当混淆矩阵, 对应于ROC曲线上当一个点, ROC曲线就反应了FPR和TPR之间权衡当情况, 通俗的说, 即在TPR随着FPR递增的情况下, 谁增长的更快, 快多少的问题. TPR增长的越快, 曲线越往上弯曲, AUC就越大, 反应了模型的分类性能就越好. 当正负样本不平衡时, 这种模型评价方式比起一般当精确度评价方式的好处尤其显著.
AUC(Area Under Curve)
AUC被定义为ROC曲线下的面积, 显然这个面积的数值不会大于1. 由于ROC曲线一般都处于y=x这条直线的上方, 所以AUC的取之范围在0.5和1之间. AUC作为数值可以直观的评价分类器的好坏, 值越大越好.
AUC的值一般要求在0.7以上.
模型评估
回归结果度量
- explained_varicance_score, 可解释方差的回归评分函数
- mean_absolute_error, 平均绝对误差
- mean_squared_error, 平均平方误差
模型评估总结_分类算法评估方式
| 指标 | 描述 | scikit-learn函数 |
|---|---|---|
| Precision | 精确度 | from sklearn.metrics import precision_score |
| Recall | 召回率 | from sklearn.metrics import recall_score |
| F1 | F1指标 | from sklearn.metrics import f1_score |
| Confusion Matrix | 混淆矩阵 | from sklearn.metrics import confusion_matrix |
| ROC | ROC曲线 | from sklearn.metrics import roc |
| AUC | ROC曲线下的面积 | from sklearn.metrics import auc |
| Mean Square Error(MSE, RMSE) | 平均方差 | from sklearn.metrics import mean_squared_error |
| Absolute Error(MAE, RAE) | 平均方差 | from sklearn.metrics import mean_absolute_error, median_absolute_error |
| R-Squared | 平均方差 | from sklearn.metrics import r2_score |
数据清洗和转换
- 实际生产环境中机器学习比较耗时的一部分
- 大部分机器学习模型所处理的都是特征, 特征通常是输入变量所对应的可用于模型的数值表示
- 大部分情况下, 收集到的数据需要经过预处理之后才能够被算法所用, 预处理的操作包括以下几个部分:
- 数据过滤
- 处理数据缺失
- 处理可能的异常, 错误或异常值
- 合并多个数据源数据
- 数据汇总
- 对数据进行初步的预处理, 需要将其转换为一种适合机器学习模型的表示形式, 对许多模型来说, 这种表示就是包含数值数据的向量或者矩阵
- 将类别数据编码成为对应的数值表示(一般使用1-of-k方法)-dumy
- 从文本数据中提取有用的数据(一般使用词袋法或者TF-IDF)
- 处理图像或者音频数据(像素, 声波, 音频, 振幅<傅立叶变换>)
- 数值数据转换为类别数据以减少变量的值, 比如年龄分段
- 对数值数据进行转换, 比如对数转换
- 对特征进行正则化, 标准化, 以保证同一模型的不同输入变量的值域相同
- 对现有变量进行组合或转换以生成新特征, 比如平均数, 可以做虚拟变量不断尝试
类型特征转换1-of-k(哑编码)
- 将非数值型的特征值转换为数值型的数据
- 假设变量的取值有k个, 如果对这些值用1到k编序, 则可用维度为k对向量来表示一个变量对值. 在这样的向量里, 该取值所对应的序号所在的元素为1, 其他元素均为0.
文本数据抽取
- 将一个文本当作一个无序的数据集合, 文本特征可以采用文本中的词条T进行体现, 那么文本中出现的所有词条及其出现的次数就可以体现文档的特征
- TF-IDF, 词条的重要性随着它在文件中出现的次数成正比增加, 但同时会随着它在语料库中出现的频率成反比下降;
- 词条在文本中出现的次数越多, 表示该词条对该文本的重要性越高
- 词条在所有文本中出现的次数越少, 说明这个词条对文本的重要性越高
- TF(词频)指某个词条在文本中出现的次数, 一般会将其进行归一化处理(该词条数量/该文档中所有词条数量)
- IDF(逆向文件频率)指一条词条重要性的度量, 一般计算方式为总文件数目除以包含该词语之文件的数目, 再将得到的商取对数得到. TF-IDF即TF*IDF
1 | from collections import defaultdict |
回归算法
回归算法是一种有监督算法,
- 线性回归
- Logistic回归
- Softmax回归
- 梯度下降
- 特征抽取
- 线性回归案例
回归算法认知
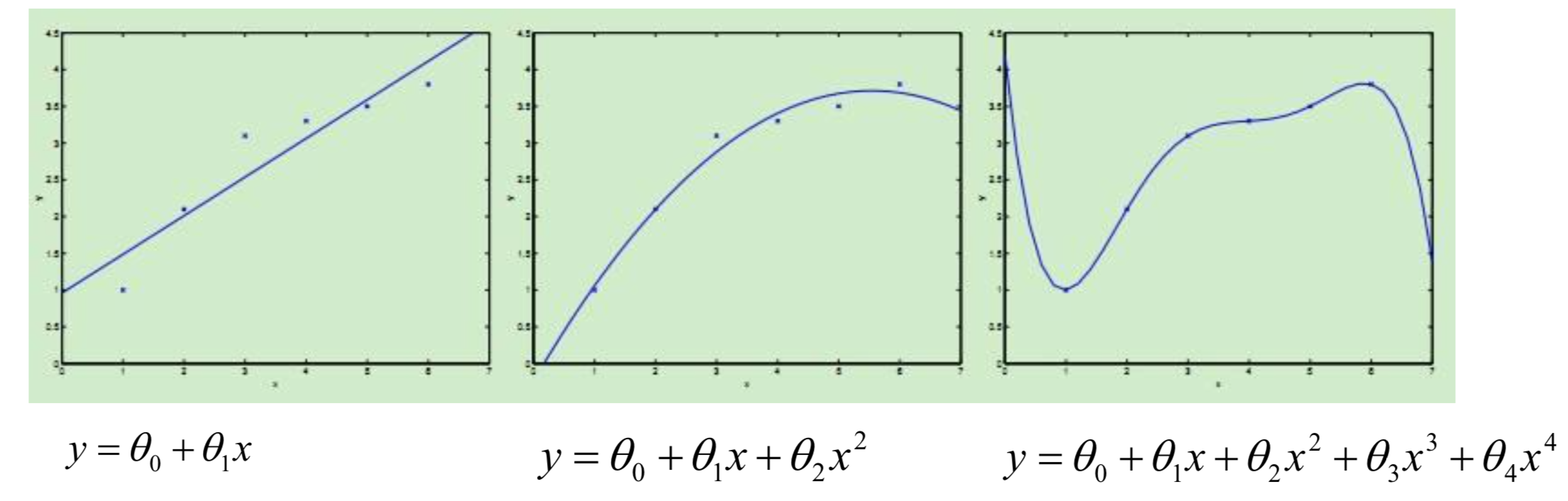
通过房屋面积预测房价, 如下图所示: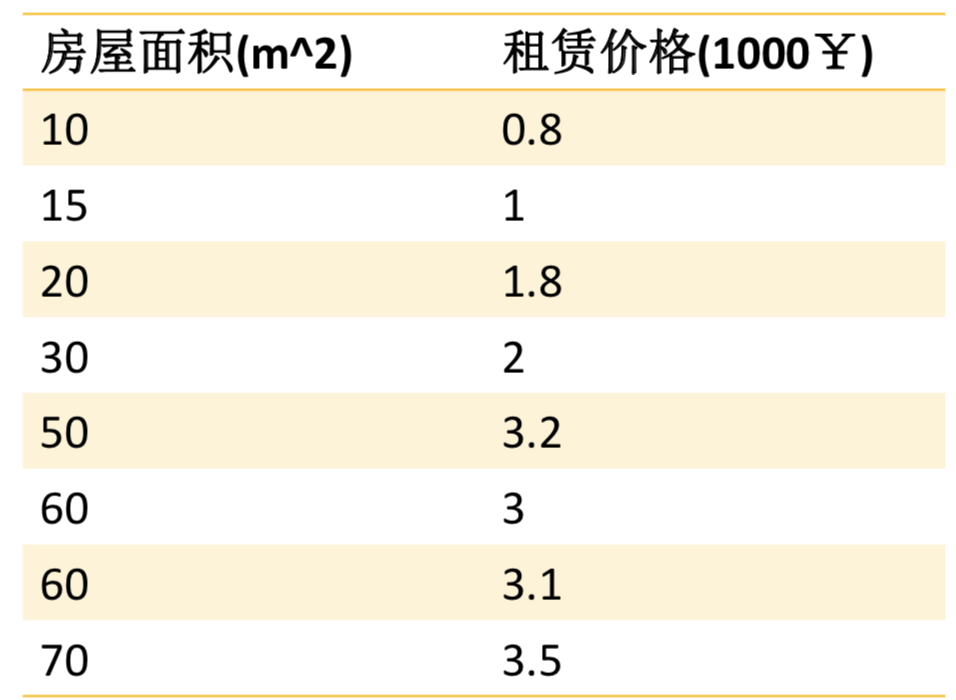
如果影响房价的还有房间数量, 那么: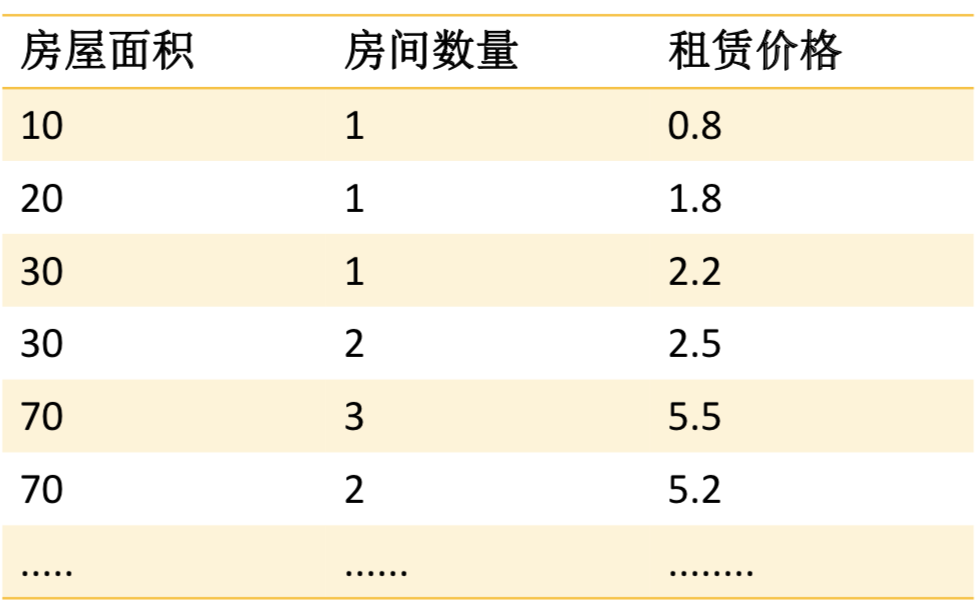
那么问题的解决依赖于如下的方程:
最后就是要计算出$\theta$的值, 并选择最优的$\theta$值构成算法公式
那么它的似然函数为:
- 误差$\epsilon^{(i)}(i \le i \le n)$是独立同分布的, 服从均值为0, 方差为某定值$\sigma^2$的高斯分布(查看中心极限定理)
- 在实际中, 很多随机现象可以看作是众多因素的独立影响的综合反应, 往往服从正态分布
似然函数
当给定某个样本值x的时候, 那么得到的实际值y的概率是多少
| 误差 | 概率 | 预测值是实际值的概率 |
|---|---|---|
| $\epsilon \downarrow$ | p $\rightarrow$ 1 | 预测值是实际值的概率越大 |
| $\epsilon \uparrow$ | p $\rightarrow$ 0 | 预测值是实际值的概率越大 |
上述只是一个样本, 概率越等于1越好, 如果对m个样本的概率进行相乘得到联合概率(样本与样本之间独立的), 这样就得到一个似然函数
对数似然, 目标函数及最小二乘法
$\theta$的求解过程
即让$J(\theta)$最小的时候, $\theta$的取值, 这就是最小二乘法
最小二乘法的参数最优解
参数解析式
X为特征矩阵, Y为目标属性, 如果一个矩阵可逆, 那么它的行列式大于0才可以
最小二乘法的使用要求矩阵$X^TX$是可逆的; 为了防止不可逆或者过拟合问题的存在, 可以增加额外的数据影响, 导致最终的矩阵是可逆的
证明如下:
而$x^Tx$是半正定矩阵, 要想$\mu^TA\mu > 0$
而$\mu^Tx^Tx\mu + \mu^T\mu > 0$
那么中间的一定是大于0的, 就一定是正定矩阵,而正定矩阵是可逆的
另外一种理解方式
目标损失函数(loss/cost function)
- 0-1损失函数 $J(\theta) = \begin{cases}1, Y \ne f(X)\\ 0, Y = f(X) \end{cases}$
- 感知损失函数 $J(\theta) = \begin{cases}1, \vert Y - f(X) \vert > t\\ 0, \vert Y - f(X) \vert \leq t\end{cases}$
- 平方和损失函数
- 绝对值损失函数
- 对数损失函数
0-1损失函数在分类中用的比较多
感知损失函数用的也比较多, 稍微一变就是SVM
对数损失函数会用在逻辑回归中
误差
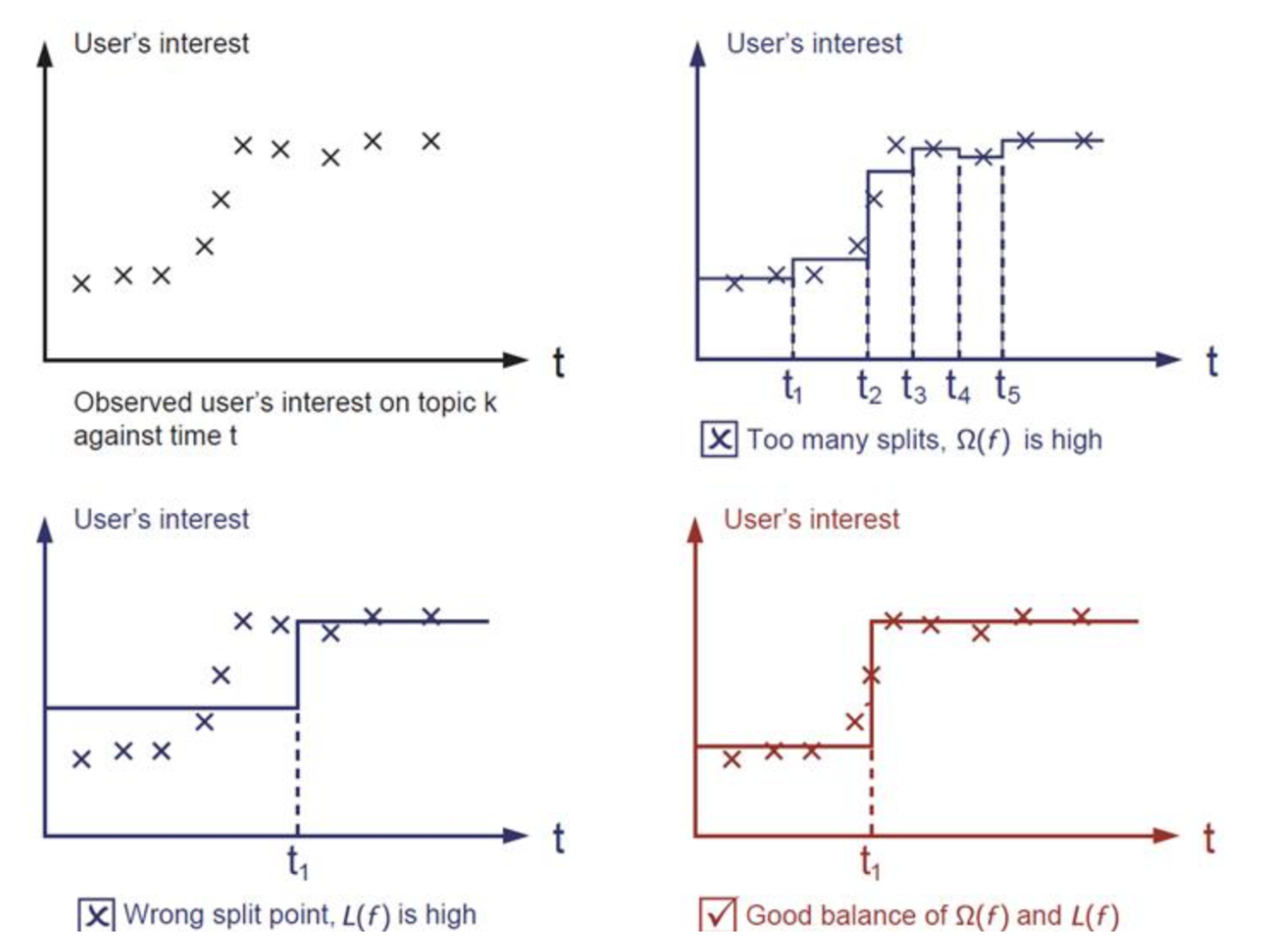
误差分为期望误差($L(f)$)和方差误差($\Omega(f)$)
偏差误差和方差之间的区别和联系
05.avi_30:00
多项式扩展就是将特征与特征之间进行融合,从而形成新的特征的一个过程; 从数学上来讲就是将低维度空间上的点映射到高维度空间中, 本身属于特征工程的一种操作.
如果模型在训练集上效果非常好, 而在训练集上效果不好, 那么认为这个时候存在过拟合的情况; 多项式扩展的时候, 如果指定的阶数比较大, 那么有可能导致过拟合, 从线性回归来讲, 认为训练出来的模型参数值越大, 就表示越存在过拟合的情况.
线性回归的过拟合
- 目标函数 $J(\theta) = \displaystyle \frac{1}{2}\displaystyle\sum_{i=1}^{m}{(h_\theta(x^{(i)}) - y^{(i)})^2}$
- 为了防止数据过拟合, 即$\theta$值的样本空间不能过大或者过小, 可以在目标函数增加一个平方和损失:
$J(\theta) = \frac{1}{2}\displaystyle\sum_{i=1}^{m}{(h_\theta(x^{(i)}) - y^{(i)})^2} + \lambda \displaystyle\sum_{i=1}^{n}\theta_{j}^2$, 前面的一项体现的是期望误差, 后面一项体现的是模型的复杂度误差 正则项(norm): $\lambda \displaystyle\sum_{i=1}^{n}\theta_{j}^2$, 此正则项叫做L2-norm, 此外还有L1-norm: $\lambda \displaystyle\sum_{i=1}^{n}\vert \theta_{j} \vert$
- L2-norm(Ridge回归, 岭回归): $J(\theta) = \frac{1}{2}\displaystyle\sum_{i=1}^{m}{(h_\theta(x^{(i)}) - y^{(i)})^2} + \lambda \displaystyle\sum_{i=1}^{n}\theta_{j}^2, \lambda > 0$
- L1-norm(LASSO回归): $J(\theta) = \frac{1}{2}\displaystyle\sum_{i=1}^{m}{(h_\theta(x^{(i)}) - y^{(i)})^2} + \lambda \displaystyle\sum_{i=1}^{n}\vert \theta_{j} \vert, \lambda > 0$, LASSO回归中间很容易出现稀疏解, 即很多0的情况; L1-norm的求解方式为坐标轴下降法
为了解决过拟合问题, 可以选择在损失函数中加入惩罚项(对于系数过大的惩罚), 分为L1-norm和L2-norm
模型效果判断
- MSE, 误差平方和, 越趋近于0表示模型越拟合训练数据
- RMSE, MSE的平方根, 作用同MSE
- $R^2$, 取值范围$(-\infty, 1]$, 值越大表示模型越拟合训练数据; 最优解是1, 当模型预测为随机值的时候, 有可能为负; 若预测值恒为样本值期望, $R^2$为0
- TSS, 总平方和, 表示样本之间的差异情况, 是伪方差的m倍
- RSS, 残差平方和, 表示预测值和样本值之间的差异, 是MSE的m倍
Elastic Net
同时使用L1正则和L2正则的线性回归模型称为Elastic Net算法(弹性网络算法)
该公式中p表示选中L1-norm的概率是多少, 选中L2-norm的概率是多少
机器学习调参
- 实际中对于各种算法模型, 需要获取$\theta$, $\lambda$, $p$的值, $\theta$的求解其实就是算法模型的求解, 一般不需要开发人员的参与(算法已经实现), 主要需要求解的是$\lambda$和$p$的值(超参), 此过程叫做调参
- 交叉验证, 将训练数据分为多份, 其中一份进行数据验证并获取最优的超参$\lambda$和$p$, 比如十指交叉验证和五指交叉验证(scikit-learn中默认)
注: $y_i$为样本值, $\hat{y_i}$为预测值, $\overline{y_i}$为均值
梯度下降算法
- 目标函数$\theta$求解, $J(\theta) = \displaystyle \frac{1}{2}\displaystyle\sum_{i=1}^{m}{(h_{\theta}{(x^{(i)})} - y^{(i)})^2}$
- 初始化$\theta$(随机初始化, 可以初始化为0)
- 沿着负梯度方向迭代, 更新后的$\theta$使$J(\theta)$更小, $\theta = \theta - \alpha \cdot \displaystyle \frac{\partial J(\theta)}{\partial \theta}$, $\alpha$为学习率或者步长
求解如下:
批量梯度下降法(BGD)
随机梯度下降法(SGD)
线性回归的扩展
- 线性回归针对的是$\theta$而言, 对于样本本身, 样本可以是非线性的
局部加权回归
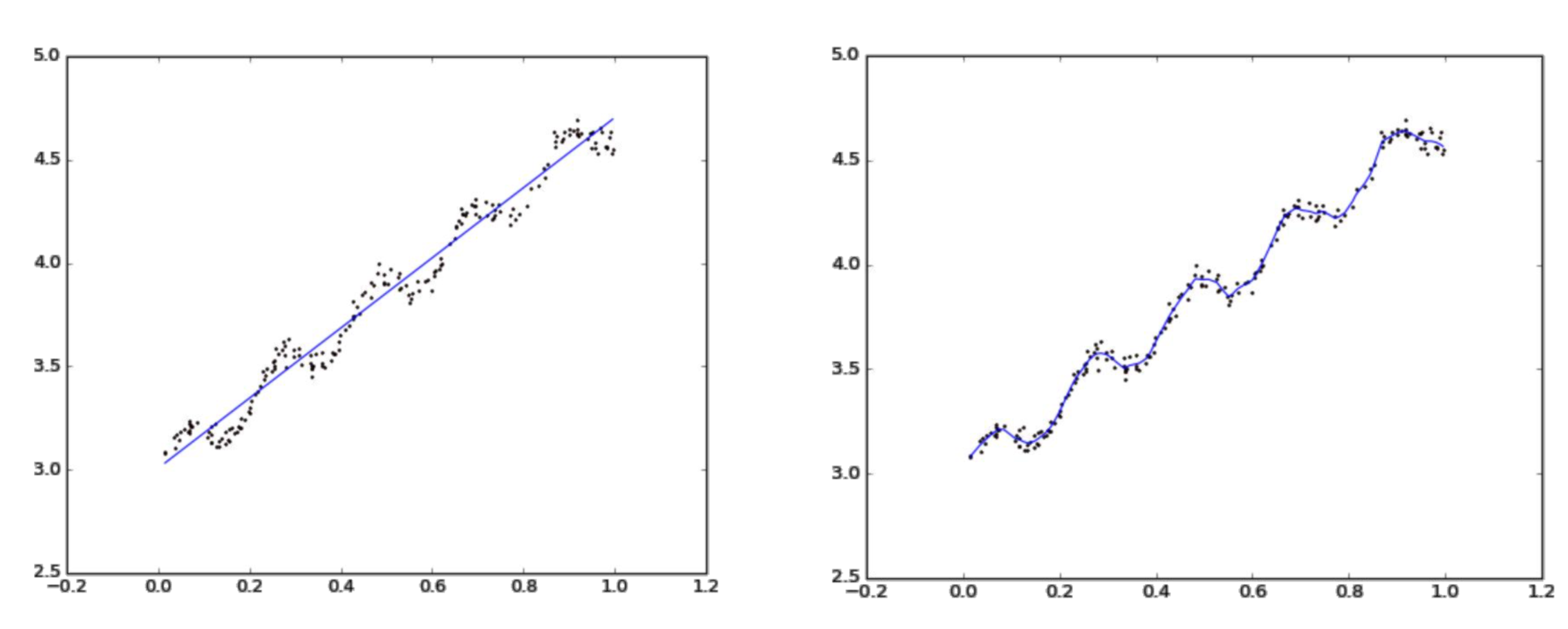
普通线性回归损失函数为:
局部加权回归损失函数为:
- $w^{(i)}$是权重, 根据预测的点与数据集中的点的距离来为数据集中的点赋权值, 当某点离要预测的点越远, 其权重越小, 否则越大. 常用值选择公式为:该函数为指数衰减函数, 其中$k$为波长参数, 它控制了权值随距离下降的速率
一般实际工作中, 当线性模型的参数接近0的时候, 我们认为当前参数对应的那个特征属性在模型判断中没有太大的决策信息, 所以对于这样的属性我们可以删除; 一般情况下, 如果是手动删除的话, 选择小于$1e-4$的特征属性
Logistic回归
Logistic/Sigmoid函数, $\displaystyle p = h_\theta(x) = g(\theta^Tx) = \frac{1}{1 + e^{-\theta^Tx}}$, p是个概率值
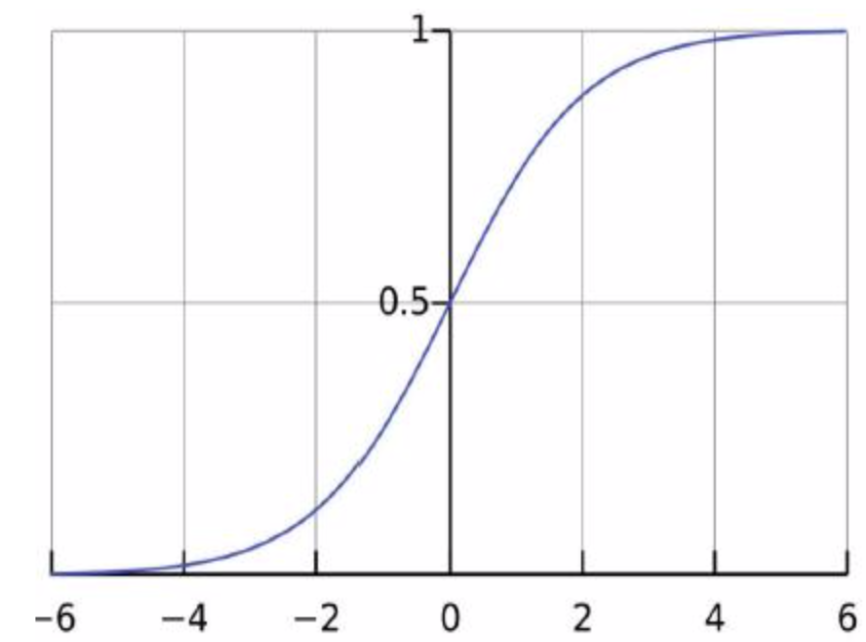
Logistic回归及似然函数
| y=1 | y=0 | |
|---|---|---|
| $p(y \mid x)$ | $\theta$ | $1 - \theta$ |
假设:
似然函数:
最大似然/极大似然函数的随机梯度
对数似然函数为:
Logistic回归$\theta$参数求解
极大似然估计与Logistic回归损失函数
Softmax回归
- softmax回归是logistic回归的一般化, 适用于K分类问题, 第K类的参数为向量$\theta_k$, 组成的二维矩阵为$\theta_{k \ast n}$
- softmax函数的本质是将一个K维的任意实数向量压缩(映射)成另一个K维的实数向量, 其中向量中的每个元素取值都介于(0, 1)之间
- softmax回归概率函数为:
softmax算法原理
softmax算法损失函数
softmax算法梯度下降法求解
summary
- 线性模型一般用于回归问题, Logistic和 softmax模型一般用于分类问题
- 求$\theta$的主要方式是梯度下降法, 梯度下降法是参数优化的重要手段, 主要是SGD, 适用于在线学习以及跳出局部极小值
- Logistic和softmax回归是实践中解决分类问题的最重要的方法
- 广义线性模型对样本要求不必要服从正态分布, 只需要服从指数分布簇(二项分布, 泊松分布, 伯努利分布, 指数分布即可); 广义线性模型的自变量可以是连续的也可以是离散的
鸢尾花数据
ravel和flatten
ravel是将多维数据转换为一维数据
线性回归+多项式扩展
- 如果数据本身不是线性关系, 那么直接使用线性回归模型效果不会体太好, 存在欠拟合
- 数据在低维空间中不是线性关系, 但是如果将数据映射到高维空间的时候, 数据就有可能变成线性关系, 从而就可以使用线性回归
- 如果映射的维度特别高, 那么数据就会完全变成线性的, 从而训练出来的模型会非常的契合训练数据; 但是实际上的数据可能会和训练数据存在一定的差距, 从而可能会导致模型在其他数据集上的效果不佳, 可能存在过拟合
过拟合
- 表现形式: 模型在训练集上效果非常好, 但是在测试集上效果不好
- 产生原因: 进入算法模型训练的这个数据集特别契合算法模型, 导致训练出来的模型非常完美, 但是实际的数据一定存在和训练集数据不一致的地方, 这个不一致就导致模型在其他数据集上效果不佳
- 解决方案: L1-norm和L2-norm
Logistic回归
- 本质上是一个二分类算法, 计算的是样本X属于一个类别的概率p, 样本属于另外一个类别的概率为1-p
- 最终认为样本X属于概率最大的那一个类别
softmax回归
- 与Logistic回归的区别在于, softmax是一个多分类算法, 需要计算样本属于某一个类别的概率, 最终认为样本属于概率最大的那一个类别
- softmax会为每个类别训练一个参数$\theta$向量, 所以在softmax中需要求解的参数其实是一个由k个向量组成的$\theta$矩阵
持久化, 管道, 模型效果评估, 交叉验证
KNN
- 理论/原理: 认为”物以类聚, 人以群分”, 相同/近似样本在样本空间中是比较接近的, 所以可以使用和当前样本比较接近的的其他样本的目标属性作为当前样本的预测值
- 预测规则:
- 分类: 多数投票或者加权多数投票
- 回归: 平均值或者加权平均值
- 权重一般选择是与距离成反比
- 相似度度量
需要找相似的样本, 认为样本的特征向量在空间中的点之间的距离体现了样本之间的相似性, 越近的点越相似, 一般使用欧几里得距离 - 寻找最近邻的样本
- 暴力的方式, 计算所有样本到当前样本的距离, 然后再获取最近的k个样本
- KD-Tree方式, 通过构建KD-Tree, 减少计算量
决策树
集成学习
考虑: 虽然抽样数据在一定程度上体现了样本数据的特性, 所以我们用样本数据模型来预测它的全体数据. 但是数据与数据之间是存在一定的差异性的, 那么可以认为在当前数据集的模型有可能会出现不拟合生产环境中数据的情况 -> 过拟合;在决策树中, 进行划分特征属性选择的时候, 如果选择最优, 表示这个划分在当前数据集上一定是最优的, 但是不一定在全体数据集上最优; 在随机森林中, 如果每个决策树都是选择最优的进行划分的话, 就会导致所有子模型(内部的决策树)很大程度/概率上会使用相同的划分属性进行数据的划分, 就会特别容易导致过拟合, 所以在随机森林中, 选择划分属性的时候一般使用随机的方式选择
如果涉及到权重的话, 一般都是将错误率/正确率/距离/MSE/MAE等指标进行转换得到的
随机森林(Random Forest)推广算法
RF算法在实际应用中具有比较好的特性, 应用也比较广泛, 主要应用在分类, 回归, 特征转换, 异常点检测等, 常见的RF变种算法有:
- Extra Tree
- Totally Random Trees Embedding(TRTE)
- Isolation Forest